 Let me preface this by saying I am a communications major, a lover of language and all things related to the humanities, following the auspices of the left brain. Science, statistics, numbers, data – that was for my logically-minded friends. Attending a research university, I was constantly surrounded by studies, which as you guessed it, are based off of piles and piles of data. It’s not that I didn’t understand the importance of data, it’s that I just never loved it. As a communications major I tended to shy away from numbers. (Okay, more like run flailing in the opposite direction as though my life depended on it.) Turns out numbers are a very real part of marketing, if not the crux of every marketing campaign. It allows you to measure what is working for your goals and what needs adjustment.
Let me preface this by saying I am a communications major, a lover of language and all things related to the humanities, following the auspices of the left brain. Science, statistics, numbers, data – that was for my logically-minded friends. Attending a research university, I was constantly surrounded by studies, which as you guessed it, are based off of piles and piles of data. It’s not that I didn’t understand the importance of data, it’s that I just never loved it. As a communications major I tended to shy away from numbers. (Okay, more like run flailing in the opposite direction as though my life depended on it.) Turns out numbers are a very real part of marketing, if not the crux of every marketing campaign. It allows you to measure what is working for your goals and what needs adjustment.
Generally speaking, I love the insights it gives, the conclusions it reaches. I just don’t enjoy the process of data collection in order to reach those conclusions. But who does? With data tied to many different sources, and housed in varying formats, it’s not easy to make it come together in one simple report. I’d like my data handed to me, preferably on a silver platter. Yes, well, that’s not how it works. And that’s not how it should work. In order to really understand the insights and not be misled by false assumptions, you should be able to understand where this data is coming from, how things are being measured, and what the goals are behind it.
Working at a software company, whose product deals with a ton of data and is designed for companies processing it to perform their reporting, I’ve had to become more comfortable with it. In any job this is a valuable skill to possess. Being able to deliver reports and present your work and results to the company/client/manager is a very necessary part of any business, and one that CEOs and execs place a lot of stake in. Not only that, it puts a tangible number to your work you can point to, to assess improvements and successes.
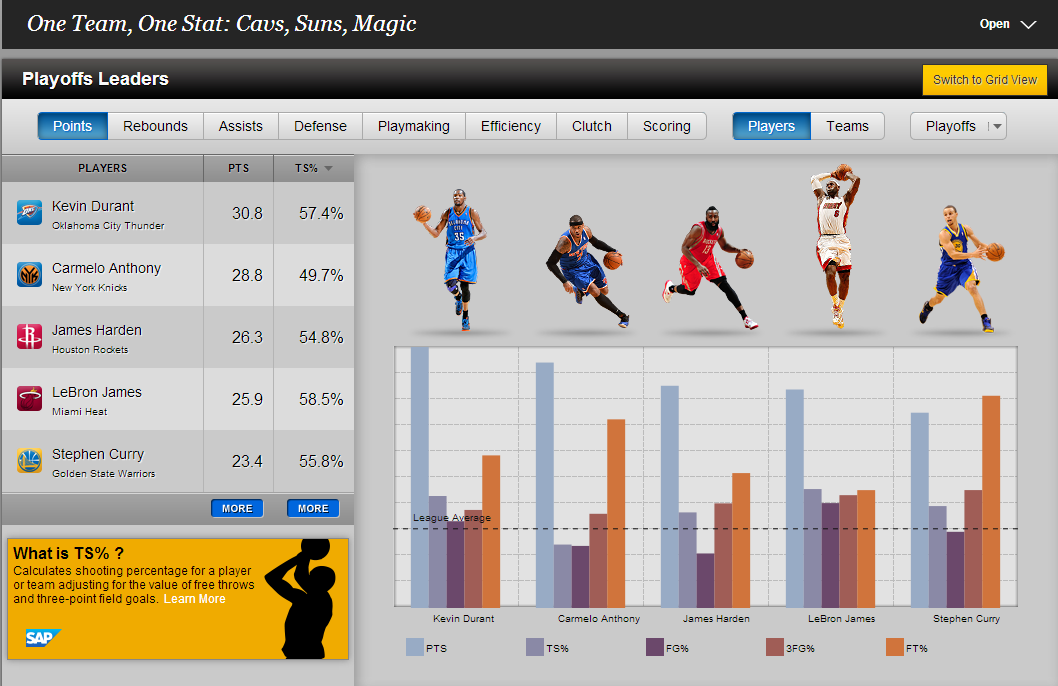
While there is this necessary business side to data collection, that doesn’t have quite the same motivation to learning to fully appreciate it. As I dove deeper into the weeds – spreadsheets, SSRS, Big Data, dark data, and servers – I discovered the ways in which people were using these numbers, the artful approach to using and displaying the information that is being collected. My coworkers showed me spreadsheets can be the springboard for masterpieces (see: Baking Cookies in Excel and Making Art with Excel). Speaker and data visualization blogger, Cole Nausbaumer, showed me you can infuse creativity into numbers. In her Storytelling with Data blog, she shows the meshing of the creativity behind presenting your data in a way people can relate to and process it: the age old art of storytelling. Now that is something to which I can relate. (If you haven’t yet, you should read her blog, and pick up tricks on data visualization.)
Along the same lines of displaying your data, Continue reading How I Learned to Love My Data: Gobbles and Gobbles of Data




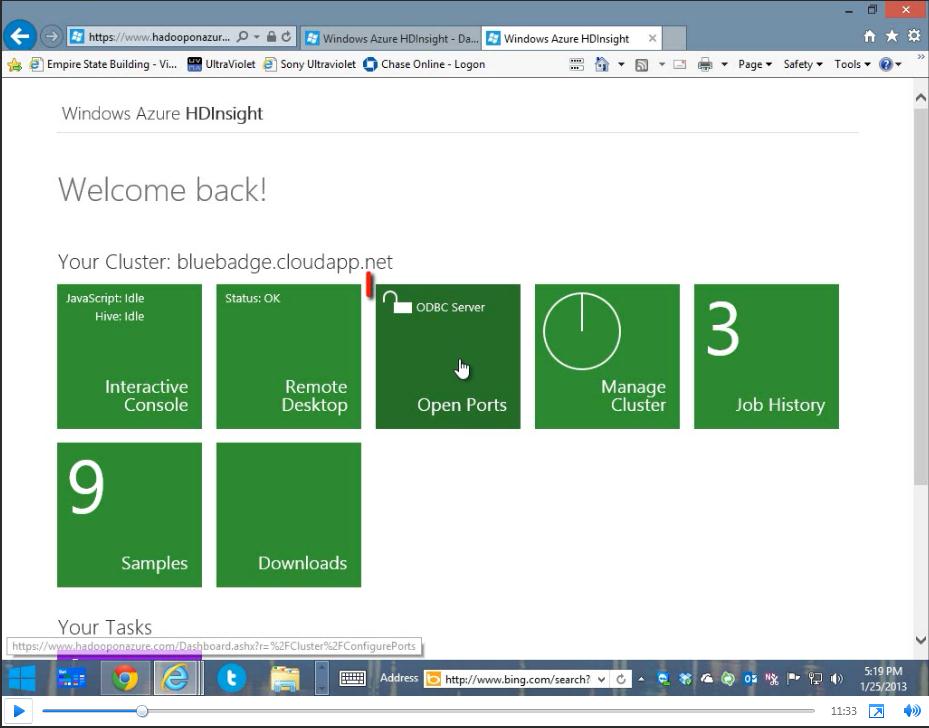 We partnered with Andrew Brust from Blue Badge Insights to integrate OfficeWriter with Hadoop and Big Data. Taking existing OfficeWriter sample projects, Andrew discusses how he created two demos showing OfficeWriter’s capabilities to work with Big Data. One demo uses C#-based MapReduce code to perform text-mining of Word docs. The other demo focuses on connecting to Hadoop through Hive.
We partnered with Andrew Brust from Blue Badge Insights to integrate OfficeWriter with Hadoop and Big Data. Taking existing OfficeWriter sample projects, Andrew discusses how he created two demos showing OfficeWriter’s capabilities to work with Big Data. One demo uses C#-based MapReduce code to perform text-mining of Word docs. The other demo focuses on connecting to Hadoop through Hive.





{kind=link}